xLearn 大规模机器学习¶
我们在这一节里主要展示如何使用 xLearn 来处理大规模机器学习问题。近年来,快速增长的海量数据为机器学习任务带来了挑战。例如,我们的数据集可能会用数千亿条训练样本,这些数据是不可能被存放在单台计算机的内存中的。正因如此,我们在设计 xLearn 时专门考虑了如何解决大规模数据的机器学习训练功能。首先,xLearn 可以支持外村计算,通过利用单台计算机的磁盘来处理 TB 量级的数据训练任务。此外,xLearn 可以通过基于参数服务器的分布式架构来进行多机分布式训练。
外存计算¶
外存计算适用于那些数据量过大不能被内存装下,但是可以被磁盘等外部存储设备装下的情况。通常情况下,单台机器的内存容量从几个 GB 到几百个 GB 不等。然而,当前的服务器外存容量通常可以很容易达到几个 TB. 外存计算的核心是通过 mini-batch 的方法,在每一次的计算时只读取一小部分数据进入内存,增量式地学习所有的训练数据。外存计算需要用户设定合适的 mini-batch-size.
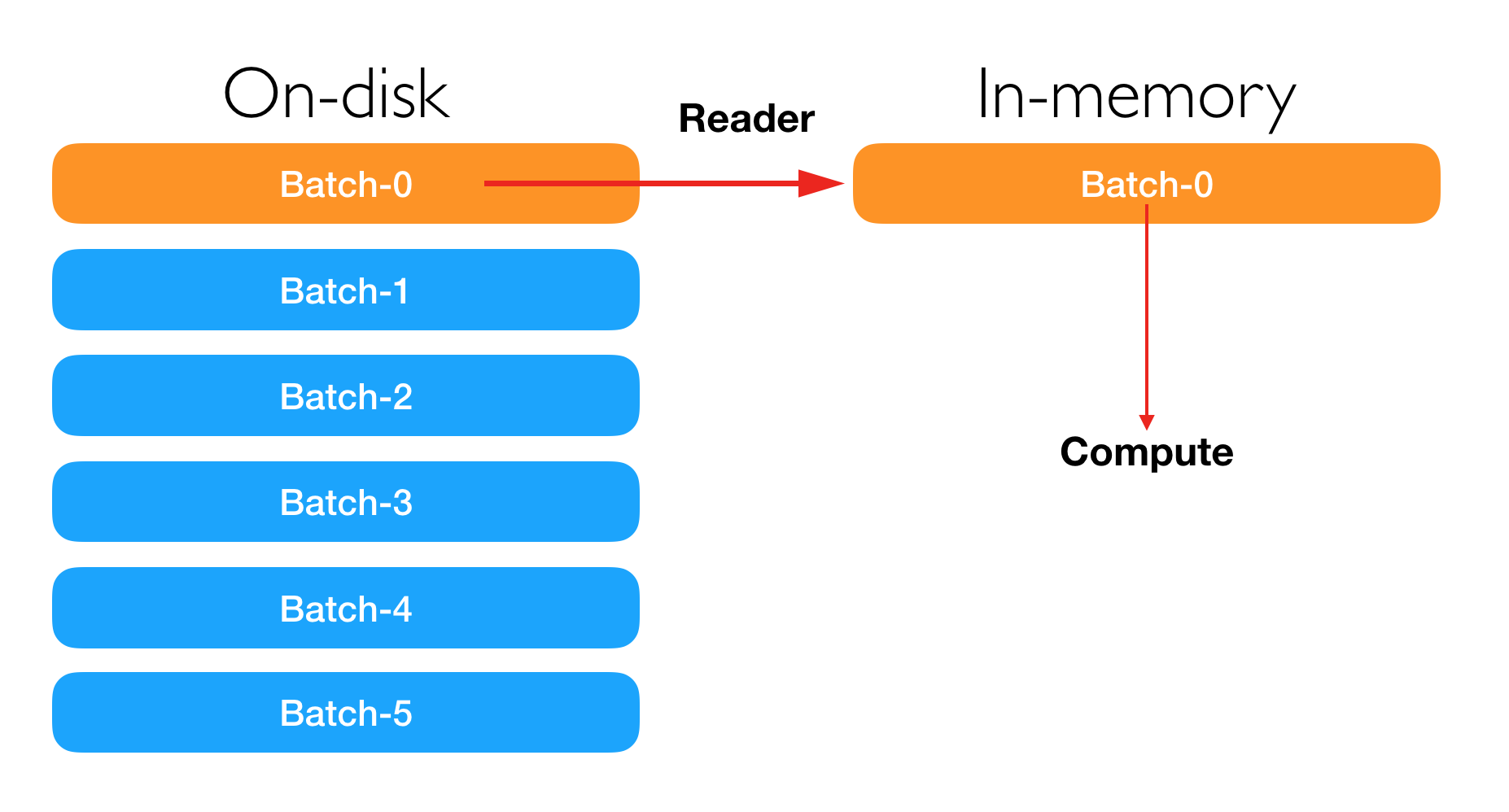
命令行接口¶
在 xLearn 中,用户可以通过设置 --disk 选项来进行外存计算。例如:
./xlearn_train ./big_data.txt -s 2 --disk
Epoch Train log_loss Time cost (sec)
1 0.483997 4.41
2 0.466553 4.56
3 0.458234 4.88
4 0.451463 4.77
5 0.445169 4.79
6 0.438834 4.71
7 0.432173 4.84
8 0.424904 4.91
9 0.416855 5.03
10 0.407846 4.53
在上述示例中,xLearn 需要花费将近 4.5 秒进行每一个 epoch 的训练任务。如果我们取消 --disk 选项,xLearn 的训练速度会变快:
./xlearn_train ./big_data.txt -s 2
Epoch Train log_loss Time cost (sec)
1 0.484022 1.65
2 0.466452 1.64
3 0.458112 1.64
4 0.451371 1.76
5 0.445040 1.83
6 0.438680 1.92
7 0.432007 1.99
8 0.424695 1.95
9 0.416579 1.96
10 0.407518 2.11
这一次,每一个 epoch 的训练时间变成了 1.8 秒。我们还可以通过 -block 选项来设置外存计算的内存 block 大小 (MB)。
用户同样可以在预测任务中使用 --disk 选项,例如:
./xlearn_predict ./big_data_test.txt ./big_data.txt.model --disk
Python 接口¶
在 Python 中,用户可以通过 setOnDisk() API 来使用外存计算,例如:
import xlearn as xl
# Training task
ffm_model = xl.create_ffm() # Use field-aware factorization machine
# On-disk training
ffm_model.setOnDisk()
ffm_model.setTrain("./small_train.txt") # Training data
ffm_model.setValidate("./small_test.txt") # Validation data
# param:
# 0. binary classification
# 1. learning rate: 0.2
# 2. regular lambda: 0.002
# 3. evaluation metric: accuracy
param = {'task':'binary', 'lr':0.2,
'lambda':0.002, 'metric':'acc'}
# Start to train
# The trained model will be stored in model.out
ffm_model.fit(param, './model.out')
# Prediction task
ffm_model.setTest("./small_test.txt") # Test data
ffm_model.setSigmoid() # Convert output to 0-1
# Start to predict
# The output result will be stored in output.txt
ffm_model.predict("./model.out", "./output.txt")
用户还可以通过 block_size 参数来设置外存计算的内存 block 大小 (MB), 例如:
./xlearn_train ./big_data.txt -s 2 -block 1000 --disk
如上所示, 我们将 block size 设置为 1000MB. 在默认的情况下, 这个值会被设置为 500.
R 接口¶
The R guide is coming soon.
分布式计算 (参数服务器架构)¶
面对海量数据,很多情况下我们无法通过一台机器就完成机器学习的训练任务。例如大规模 CTR 任务,用户可能需要处理千亿级别的训练样本和十亿级别的模型参数,这些都是一台计算机的内存无法装下的。对于这样的挑战,我们需要采用多机分布式训练。
Parameter Server (参数服务器) 是近几年提出并被广泛应用的一种分布式机器学习架构,专门针对于 “大数据” 和 “大模型” 带来的挑战。在这个架构下,训练数据和计算任务被划分到多台 worker 节点之上,而 Server 节点负责存储机器学习模型的参数(所以叫作参数服务器)。下图展示了一个参数服务器的工作流程。
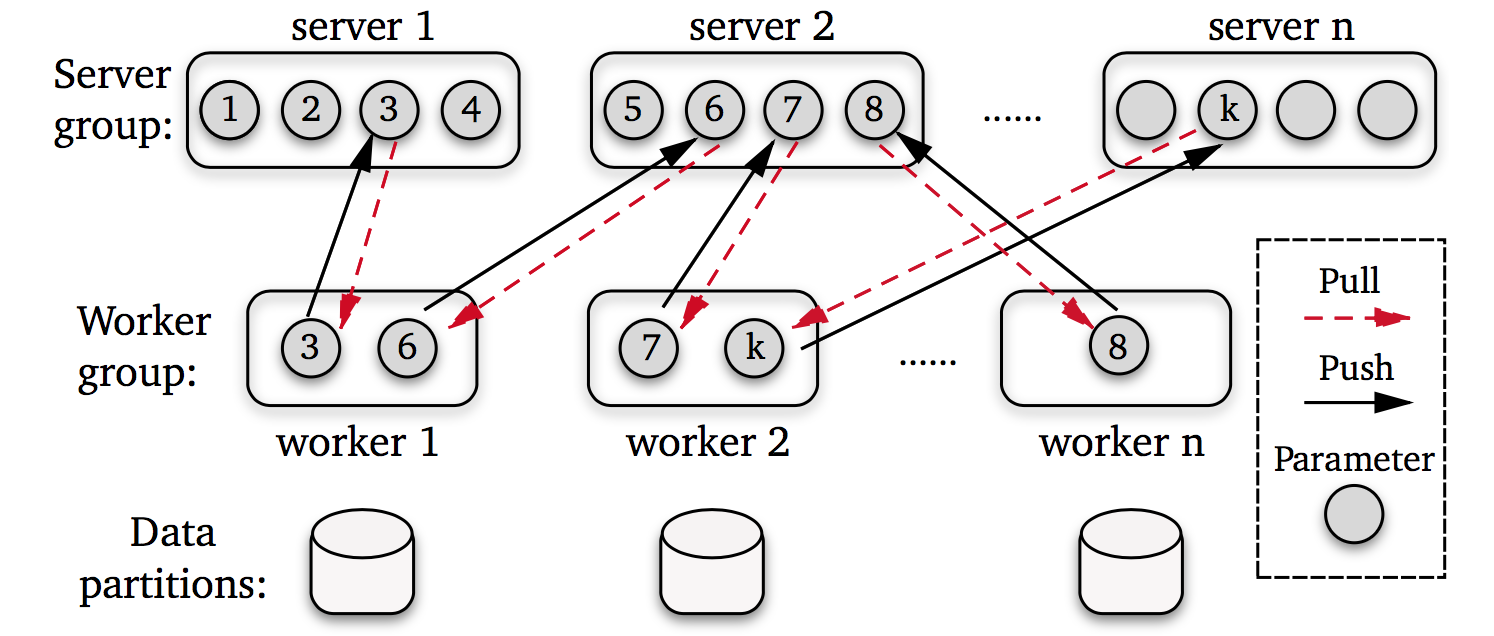
如图所示,一个标准的参数服务器系统提供给用户两个简洁的 API: Push 和 Pull.
Push: 向参数服务器发送 key-value pairs. 以分布式梯度下降为例,worker 节点会计算本地的梯度 (gradient)并将其发送给参数服务器。由于数据的稀疏性,只有一小部分数据不为 0. 我们通常会发送一个 (key,value)的向量给参数服务器,其中 key 是参数的标记位,value 是梯度的数值。
Pull: 通过发送 key 的列表从参数服务器请求更新后的模型参数。在大规模机器学习下,模型的大小通常无法被存放在一台机器中,所以 pull 接口只会请求那些当前计算需要的模型参数,而并不会将整个模型请求下来。
The distributed training guide for xLearn is coming soon.